7 de Enero de 2020 · 2 min de lectura

En TroncoMovil SL nos dedicamos al alquiler de coches ecológicos. Buscamos en internet los coches que creemos son más respetuosos con el medioambiente y nos ponemos en contacto con los concesionarios para adquirirlos y ponerlos al alcance de nuestros clientes.
En un mundo ideal tendríamos una base de datos a la que consultar cada coche en el universo según los parámetros que queremos pero los malvados del automovilismo tienen las fichas técnicas escritas para facilitar la vida a los comerciales. Así pues tenemos el texto:
“El superTronco 9000 tiene un amplio espacio para que usted vaya los más cómodo posible hasta 6 personas mientras recorre las carreteras con su suspensión a 4 ruedas. Podrá disfrutar de un maletero de más de 200L en el que caben hasta 4 barriles de cerveza. Su tracción a 4 pies le permite que su copiloto pedalee con usted para llegar a velocidades de hasta 40KM/h”
Cuando lo que nosotros quisiéramos es una tabla:
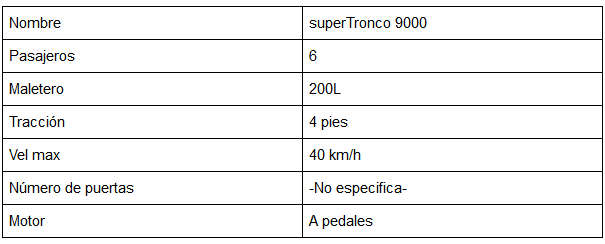
En un mundo ideal podríamos pedir a los concesionarios que nos pasaran la información formateada pero no siempre accederán y puede que nos interese automatizar la extracción, dentro de lo posible, sin tener que pedirlo a cada vez que haya un nuevo coche, así que decidimos analizar cómo extraer la información.
Siguiendo nuestro instinto humano al buscar información en un texto lo que buscamos son patrones a los que estemos acostumbrados. El caso más sencillo es el del maletero, ya que suele darse la capacidad en litros de volumen total, así pues bastará que busquemos aquello que sea un número y una L “xxxL”. Pero necesitamos que esto funcione en multitud de casos:
Incluso en el caso:
400 L con todos los asientos tumbados (300 L con las plazas levantadas)
El algoritmo debe extraer ambos valores y diferenciar cual es el máximo y en qué condiciones.
Si estás pensando “¡uf! Cómo se complica la cosa...” Tranquilo…., que ahora te explicamos cómo lo solucionamos. Si por la contra estás pensando “Esto con cuatro expresiones regulares lo soluciono”, tranquilo que por suerte no las necesitaremos.
Lo que hacemos es definir una gramática, ¿eso qué significa? Pues comenzamos definiendo un sintagma descriptor de maletero o SM (el conjunto de palabras que describen un maletero) que puede tener diferentes formatos, principalmente:
Como podéis ver la gramática permite ser recursiva y facilita las definiciones rápidas. Así pues definiendo a parte los formatos de cantidad, indicativos y diferentes condiciones solo nos faltará usar uno de los algoritmos de librerías como NLTK para el análisis gramatical.
Para entender las ventajas del uso de gramáticas y como aplicamos ML a este algoritmo no te pierdas la parte 2 de este artículo.
Si crees que tienes un problema en el que nuestro departamento de Data Science pueda ayudarte no dudes en enviarnos un correo a data@apsl.net




