21 de Febrero de 2023 · 11 min de lectura

En nuestro día a día, como usuarios de todo tipo de aplicaciones y soluciones tecnológicas lo que no queremos es perder el tiempo. Buscamos obtener la respuesta a nuestras preguntas con la máxima brevedad posible. Necesitamos buscar múltiples opciones de vuelos y hotel para comparar tarifas sin esperar minutos tediosos, además está demostrado que menores tiempos de espera llevan a mejor conversión y ventas.
Para minimizar este tiempo de respuesta, en informática, se puede intentar optimizar al máximo el sistema o, además, añadir una caché.
Seguro que todos hemos oído hablar de caché en algún momento de nuestra vida laboral, de algo abstracto que nos permite reducir el tiempo de acceso. La realidad es mucho más compleja pero, para no saturar, introduciré, los que para mí, son los tres tipos básicos:
Únicamente me centraré en las dos últimas ya que son las que más nos incumben y son las que realmente podemos controlar e implementar. Antes de nada, voy a responder a la pregunta que probablemente te hagas y no entiendas cómo es que aún no he respondido… ¿Qué es una caché?
Una memoria caché es una capa de almacenamiento de alta velocidad que almacena un subconjunto de datos, de modo que el acceso a estos sea más rápido que si se tuviera que acceder a través de la memoria principal.
Básicamente, nos podemos quedar con los siguientes puntos:
Ahora que tenemos una idea de qué es una caché y para qué sirve, me centraré en describir algunos de los tipos más comunes dividiéndolos en dos bloques principales:
Introduciré y utilizaré el mismo ejemplo en todos los tipos de carga.
Nuestra caché será un carrito de la compra que se utiliza para almacenar productos. Puede estar vacío, lleno, con algún producto, etc.
Lo primero es saber a qué me refiero con cargar una caché. Cargar una caché (también conocido como caché warming en Inglés) es, básicamente, llenarla de datos. [Se llena el carrito de compra con todos los productos que se desee]. Esto se puede hacer de diferentes maneras, pero me centraré únicamente en cuatro de ellas:
No me quiero extender mucho, por lo que introduciré los tres tipos de caché que más he utilizado en mi vida laboral.
Function Caching: Es una de las cachés más sencillas y consiste en almacenar el resultado de una función dados unos parámetros concretos (Ej: Servidores GraphQL como Apollo Server cachean el resultado de sus funciones para evitar llamadas innecesarias a los servicios de datos).
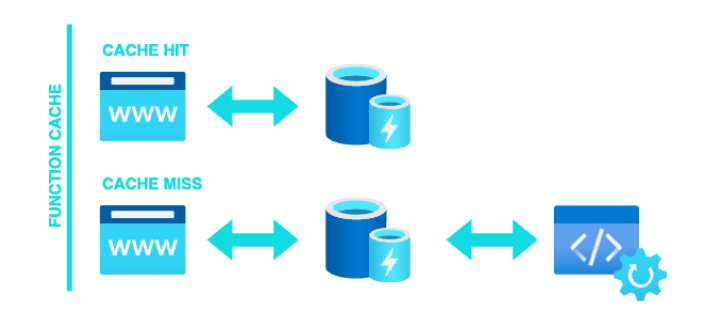
El acceso a los datos se hace de la siguiente manera:
DB Cache: El objetivo principal es almacenar datos en crudo tras ejecutar una/s consulta/s sobre la base de datos. Muy parecido a Function Caching pero el primero no tiene por qué acceder a datos, puede únicamente almacenar el resultado de un algoritmo. Además, para cachear datos en crudo, podemos tener índices a nivel de arquitectura (dependiendo de la implementación, para un acceso directo, se podría tener un índice por id, external_id, email, etc.) y diferentes funciones de acceso.
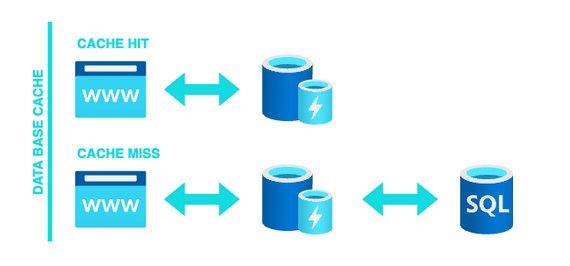
El acceso a los datos se hace de la siguiente manera:
Business Cache: El objetivo principal es almacenar datos complejos que necesitan de un procesamiento previo. Estos, a priori, suelen ser objetos de negocio que relacionan y dependen de varios modelos/funcionalidades además de necesitar un procesamiento o una gestión costosa en tiempo y recursos.
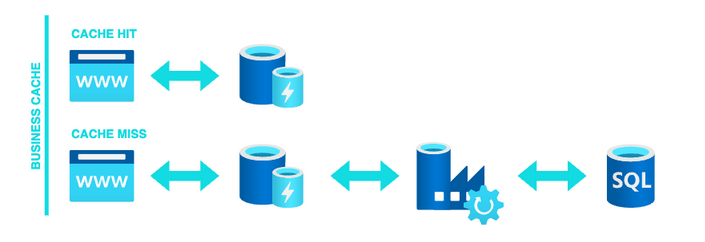
El acceso a los datos se hace de la siguiente manera:
Estamos listos para entrar en el gran mundo de las cachés navegando a través de una versión de caché distribuida. Ya sé que he explicado diferentes tipos de caché, tanto por tipo de acceso como por tipo de dato almacenado, pero quiero añadir también información breve sobre el lugar de almacenamiento.
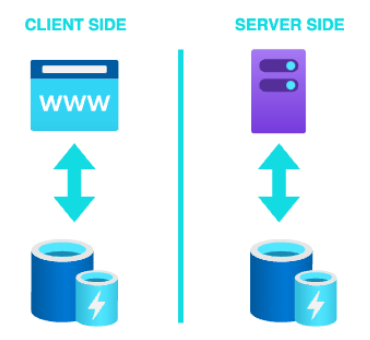
Ahora que sabemos más o menos dónde se almacenarán nuestros datos, vamos a empezar introduciendo algunos conceptos básicos que se utilizarán para llevar a cabo la implementación.
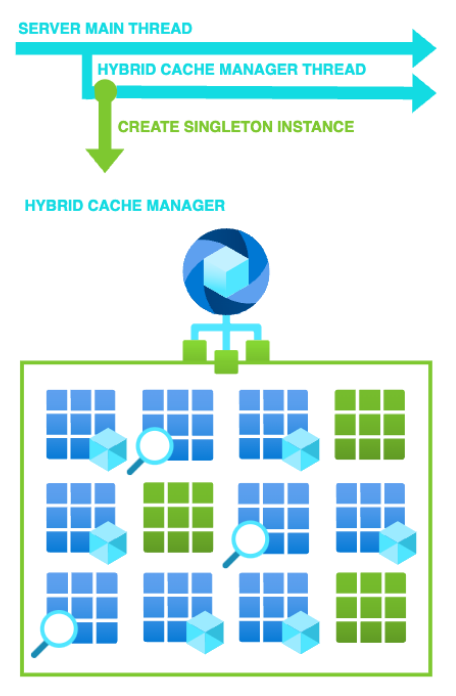
Singleton
Se asegura de que exista una única instancia de una clase, además de devolver un puntero global a dicha instancia.
Management Thread
Hilo gestor de cachés encargado de cargar, distribuir, recargar las instancias de caché individuales. Es un hilo activo en paralelo al hilo principal del servidor y permanece siempre activo (obviamente seguirá el mismo flujo que el servidor, por lo que si este se recicla, el hilo también lo hará).
Shared Access
Las instancias individuales de caché, que también llamaremos Gestores Individuales o Cache Managers también hacen uso del patrón singleton. Gracias a esto nos aseguramos de que no tengamos datos duplicados en memoria y nos evitamos la inconsistencia de datos, entre otros.
Cache Type
Dependiendo del tipo de caché configurada en el Cache Manager el hilo gestor es capaz de lanzar cargas automáticas al inicio de su ciclo de vida.
Access Time
En nuestra implementación, como ya se comentó, se hace uso de los punteros Shared del Framework ya que nos permiten el acceso compartido para todos los hilos del sistema. Es infinitamente más rápido utilizar un puntero directo que pasar por la arquitectura definida por Microsoft. El inconveniente principal de utilizar un Cache Engine Custom es la gestión de las instancias CacheManager, que se deberá realizar manualmente por el propio Engine.
Teniendo en cuenta estos conceptos básicos, vamos a ver un esquema de una posible arquitectura.
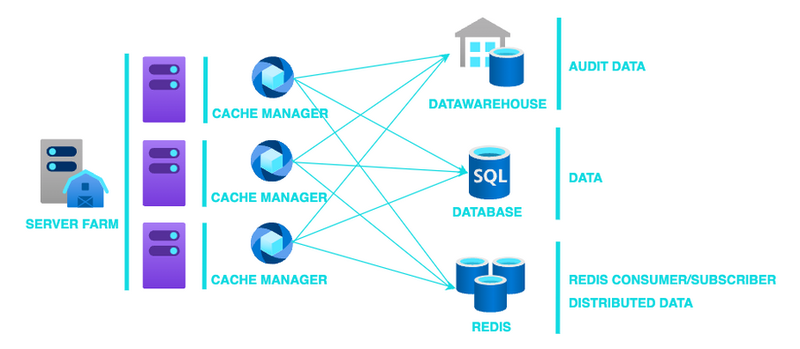
Supongamos que nuestro sistema está formado por tres servidores balanceados y no sabemos cuál de ellos podría recibir una petición concreta. En realidad, nos da igual ya que en teoría, todos ellos deberían tener el mismo código y la misma configuración.
Ahora vamos a suponer también que queremos cachear información referente a usuarios únicos del sistema.
Nuestra caché tendrá almacenados todos los usuarios con sus datos básicos identificativos (id, nombre, apellidos, documento_identidad, email, telefono, direccion_1, codigo_postal…). En este punto he supuesto muchas cosas que en la vida real se deberían tener en cuenta (qué datos cargar, activos/inactivos, validaciones, etc.).
Posteriormente entraré más en detalle, pero a grandes rasgos, el esquema anterior se podría explicar como:
Hasta este punto he estado hablando de Instancias de caché individuales, Cache Managers, gestores… Pero ¿qué son realmente?
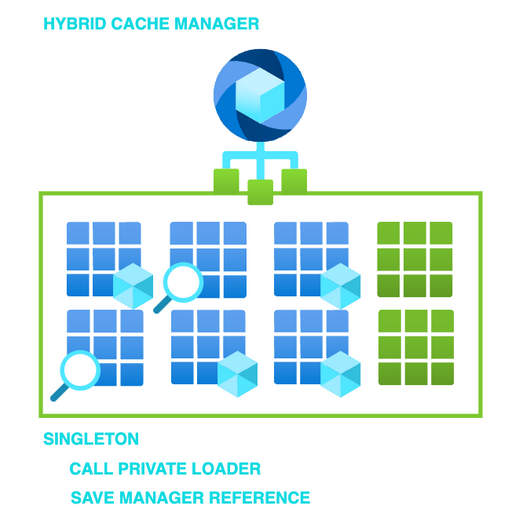
Un Cache Manager es una instancia encargada de gestionar todo lo relacionado con un tipo de datos ya sea básico o complejo. Cuando digo todo lo relacionado me refiero a carga, acceso y actualización. Además, al utilizar el patrón singleton para su creación, nos aseguramos de que únicamente tengamos una única instancia.
Las principales características serían:
Ahora que sabemos qué es un Cache Manager vamos a explicar cómo podemos cargar y cómo acceder a los datos almacenados.
Tenemos dos opciones principales: el Cacheo de Datos Genérico y el Cacheo de Datos Custom.
Cacheo de Datos Genérico
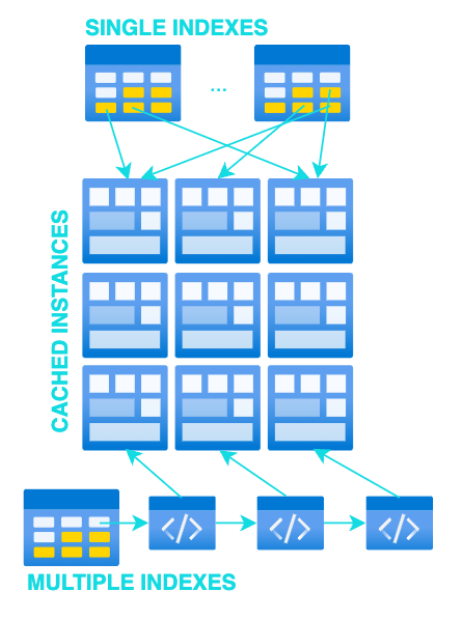
Es importante tener en cuenta que para el cacheo genérico no es necesario que el programador defina ningún tipo de estructura de datos, funciones de acceso o de indexado. Únicamente deberá definir una consulta a base de datos.
El Engine proporciona:
Cuando se llame a la función privada de carga, el manager pasará su consulta de base de datos a las funciones internas del Engine y este cargará, mapeará e indexará todos los registros.
Dado el ejemplo de Caché de Usuarios, una posible implementación tendría:
Generar Cache de Datos Custom
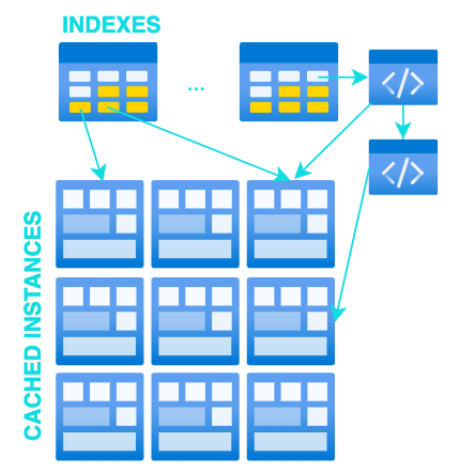
La principal diferencia entre el Custom y el Genérico es que en este caso el programador debe definir la estructura de datos, el indexado, el mapeo y las funciones de acceso a los datos. Además, al no hacer uso de las clases proporcionadas por el Engine, es él el que debe gestionar el origen de los datos (consultas a Base de Datos, funciones de cálculo, etc.).
Personalmente, esta es la más utilizada ya que da mucha más libertad a la hora de implementar las cachés. Además, suele ser más rápida al ahorrarnos clases intermedias que lo único que hacen es añadir más saltos entre punteros. Somos nosotros los que definimos los índices que queremos y somos nosotros los que elegimos la estructura de datos que queremos para nuestra caché.
Otro punto en el que es superior a la genérica es que no estamos obligados a almacenar únicamente datos planos con la misma estructura que la base de datos, podemos generar y guardar objetos de negocio complejos. El límite es nuestra imaginación.
Sabemos que podemos guardar datos en memoria del servidor, pero ¿es necesario que todos ellos realicen la carga inicial y tengan que procesar todos los datos si son compartidos entre servidores? ¿Qué pasa cuando se actualiza un registro? ¿Podemos tener ese dato actualizado sin tener que refrescar toda la información de la caché?
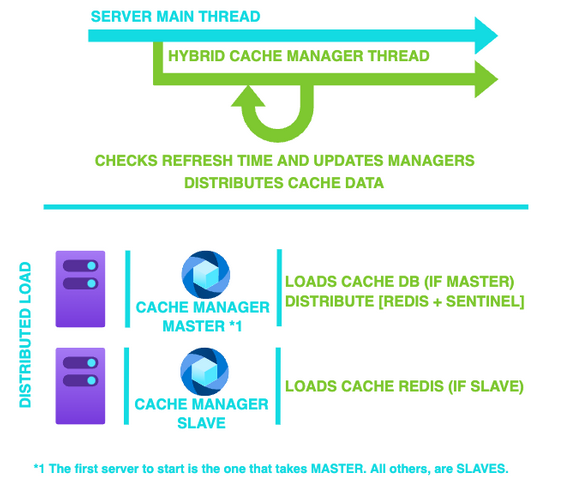
Depende de cómo se configure la caché, no sería necesario que todas las instancias de los diferentes servidores cargaran y mapearan los datos. Se podría tener un servidor que haga todo el trabajo de procesamiento (Master) y luego compartiera su estructura de datos ya creada con el resto para así ahorrarnos procesamiento innecesario y redundante.
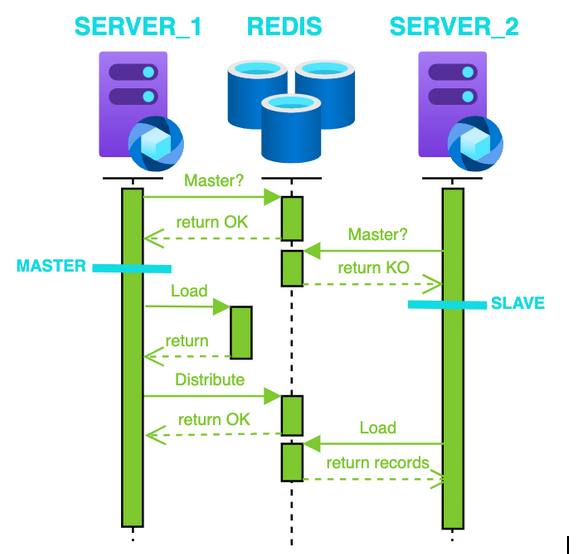
Así en cuanto se inicien todos los servidores, el primero que obtenga el token de Master será el que cargue los datos y los distribuya al resto.
Una vez tenemos los datos cargados, si queremos actualizar los registros y que esta actualización esté presente en todos los servidores, podríamos hacer uso de redis para propagar los valores.
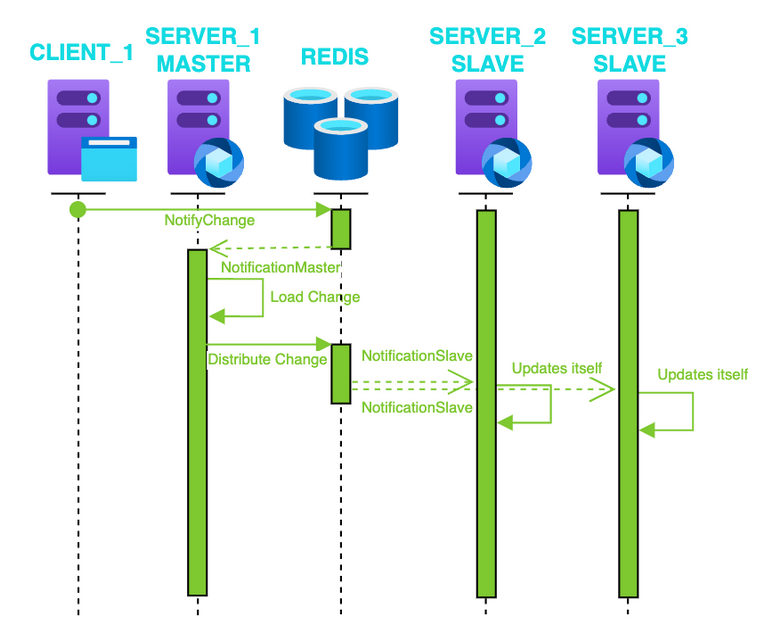
Es sencillo si seguimos el flujo que veremos a continuación:
Ahora sabemos cargar y actualizar, pero ¿qué pasa si queremos invalidar una caché? En este caso tendríamos dos opciones:
Ha sido un viaje rápido y superficial sobre el mundo de las cachés y más concretamente sobre una implementación interesante de caché distribuida. Hemos visto algunos ejemplos y sobre todo hemos entendido el concepto básico que podríamos extrapolar a cualquier sistema.
Con esto no quiero decir que sea necesario implementarlas siempre. Únicamente si el sistema lo requiere y tenemos la posibilidad de invertir. Además, su uso depende de otros muchos factores igual de importantes como los usuarios concurrentes, tiempos de acceso deseados, datos que queremos almacenar, carga del sistema, etc.











