6 de Marzo de 2023 · 7 min de lectura

Empezaré hablando del concepto matar moscas a cañonazos. Podríamos definir esta expresión como usar absurdamente recursos desmesurados y costosos, para realizar mínimas cosas o solucionar problemas ínfimos.
Pero… ¿Por qué me centro en este concepto en lugar de abordar directamente el tema a tratar? Básicamente porque están fuertemente relacionados. El problema a resolver, a priori, parecía sencillo. Yo quería implementar una solución completa, genérica y escalable… Y siempre que hablamos de código genérico, hablamos de código complejo y, en general, difícil de entender para alguien que no está acostumbrado a leerlo e interpretarlo.
Entonces, te voy a contar cómo se creó un módulo genérico y escalable, que inicialmente te parecerá overkill, pero que después de haber visto realmente cuál es el problema y cuál es la solución aplicada, verás que no lo es.
Hoy hablaré y me centraré en describir brevemente un proyecto enfocado a convertir una funcionalidad implementada en SQL en un REST Endpoint.
A sabiendas de que implementaremos un módulo complejo, deberíamos primero conocer el problema. El objetivo principal era convertir una función SQL en un endpoint. Dicha función debía actualizar N tablas relacionadas dado un identificador primario.
Pero, ¿qué actualizaba exactamente? Para responder a esta pregunta, lo más sencillo es poner un ejemplo:
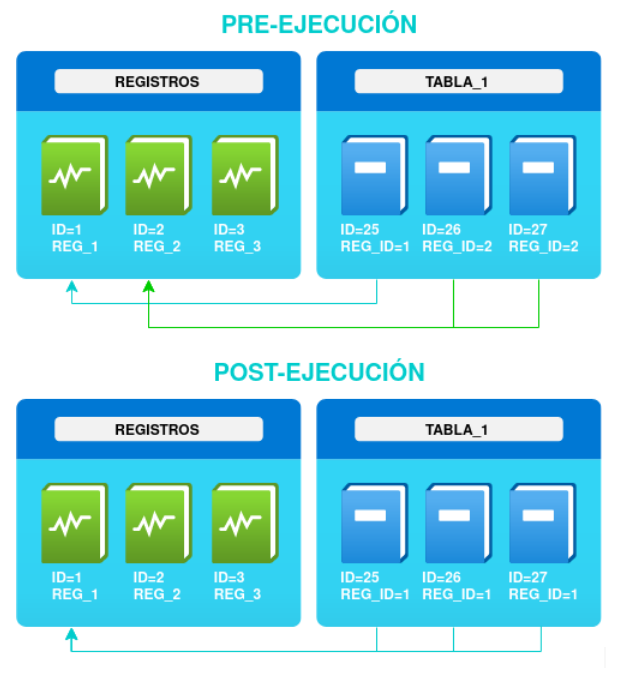
Teniendo en cuenta que tenemos los siguientes registros [REG_1 (1), REG_2 (2), REG_3 (3)] y N tablas relacionadas a estos.
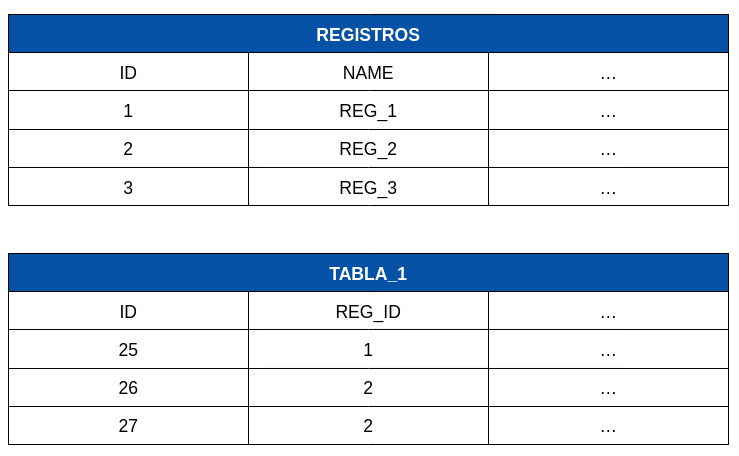
Nuestra función mágica tenía como entrada un target_id y una lista de identificadores llamada duplicated_ids. Lo que hacía era actualizar todas las tablas relacionadas estableciendo el target_id en todos los registros cuyo REG_ID estuviera dentro de duplicated_ids. Básicamente, era como un merge por fuerza bruta. Tras ejecutar la función, en nuestro ejemplo, con el valor 1 como target_id y los valores [2, 3] como duplicated_ids, los registros [26, 27] de TABLA_1 tendrían su REG_ID actualizado a 1.
Una de las razones más importantes de convertir esta funcionalidad en un endpoint era dar solución a los siguientes problemas:
Teniendo esto en cuenta, vamos a entrar al detalle centrándonos en:
La implementación empezó con varios frentes abiertos a los que debíamos dar solución. Entre ellos estaba cómo guardar información referente a los cambios realizados, cómo actualizar todas las tablas de la forma más sencilla y mantenible, cómo deshacer las actualizaciones en caso de que se haya ejecutado un merge que no debía…
Dado que trabajamos con Django, también usaré modelo/s para referirme a las tablas.
Empezaré por cómo se implementó la actualización de los modelos de manera más o menos mecánica. Mi principal objetivo era que si en un futuro se quisieran añadir más tablas, se pudiera copiar-pegar y se modificara únicamente el nombre de la clase.
Es importante saber que tenía que cargar y actualizar los datos de más de 30 modelos relacionados. Mi objetivo principal era tener una función genérica capaz de realizar la carga y la actualización a la vez. Para ello, se implementó la función `_update_model_related_id` que recibía un tipo genérico llamado `model_class` y el nombre de la propiedad que queríamos actualizar (esto era necesario ya que la columna no tenía el mismo nombre en todos los modelos relacionados).
Lo primero que hace esta función es, por medio de una clase gestora, cargar dinámicamente los queryset, objetos Django, etc. haciendo uso de reflection (`getattr(model, “objects”)`).
Una vez teníamos las instancias, se filtraban para obtener únicamente aquellas cuyo id relacionado estaba dentro de los duplicated_ids.
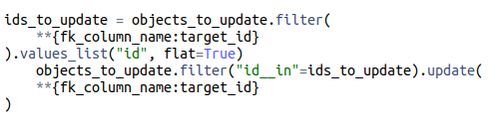
Con esta nueva lista, únicamente teníamos que lanzar un update actualizando el valor del id relacionado estableciendo el target_id.
Además de lanzar el update, se guardaba en la estructura de auditoría la información necesaria para, a posteriori, poder deshacer el merge.
Ya sabemos cómo actualizar los modelos de forma más o menos genérica. Además, en el punto anterior he hablado de guardar un registro de auditoría, pero no he especificado qué campos almacenaremos ni cómo lo haríamos.
La idea principal es definir una estructura de dos tablas:
Gracias a esta estructura es muy sencillo deshacer cualquier merge. Lo único que debemos hacer es dada una lista de audit_block_ids recorrer todos los audit_records relacionados y por medio de reflection y actualizando al revés que el merge dejar los registros con el valor antiguo. Destacar que si los registros relacionados a las claves primarias que tenemos almacenadas en las tablas de auditoría han dejado de existir, simplemente no se actualizarán al volver un paso para atrás.
En esta primera versión de la herramienta, toda la ejecución se realizaba de manera síncrona. Por lo que si cada merge tardaba 70 ms, bastaba con multiplicar por los registros de la petición para tener un aproximado del tiempo de ejecución. Más adelante, en la V2 hablaremos de por qué se convirtió todo en asíncrono.
No he hablado aún de REST porque la implementación de un endpoint no es complicada y no es mi objetivo con este texto, es únicamente nuestro punto de entrada a la herramienta. Pero supongamos que, parte de nuestra petición, tiene los siguientes datos:

Entonces, por cada registro de merging_list, se recorrerán las tuplas [target_id, duplicated_id] generando un audit_block. Además, por cada modelo actualizado se generará un audit_record relacionado a su audit_block. Teniendo en cuenta que podríamos tener que actualizar 30 modelos, estaríamos hablando de un audit_block con 30 audit_records por cada duplicated_id.
Nuestro código síncrono es muy sencillo:
Por cada registro de merging_list:
Dicho esto, tendríamos nuestra función de mergeo lista para actualizar todos los registros que queramos… Siempre y cuando no nos diera un TimeOut.
Todo era muy bonito hasta que llegaron los TimeOuts. Uno de los objetivos de mover la funcionalidad de SQL a REST era dar la posibilidad de actualizar más de un millar de registros a la vez ya que por base de datos únicamente era posible unas 100 antes de sufrir un TimeOut.
Con la primera versión, la síncrona, éramos capaces de actualizar unas 700-800 antes de llegar al TimeOut de treinta segundos. Necesitábamos la forma de ejecutar más acciones de merge al mismo tiempo. Pensamos diferentes soluciones, pero finalmente decidimos utilizar Celery para lanzar las ejecuciones por bloque asíncronamente, una tarea por bloque.
Para ello tuvimos que redefinir un poco la estructura de la función principal y añadir clases de gestión para las tareas. El cambio más importante a nivel de usuario era el pasar de una única petición a dos: una para encolar los merge y otra para comprobar el estado de las diferentes ejecuciones. Lo que se decidió fue reutilizar el endpoint actual para encolar y crear uno nuevo para consultar.
Pero claro, al necesitar consultar el estado de dichas ejecuciones se tuvo que crear un modelo TaskLog para almacenar el identificador único del audit_block, el task_id, status, resultado de la tarea y la fecha de inicio y de fin.
Además, se creó una clase específica, que heredaba de la tarea de Celery, para gestionar los estados de las tareas ejecutadas. Gracias a esto, se pudo programar la funcionalidad de before_start, on_success y on_failure, para registrar la tarea en TaskLog y actualizar el resultado y los estados.
Entonces, una vez definida la forma de almacenar la información de las tareas y la gestión de estados teníamos que actualizar la función principal de merge. Esto fue sencillo ya que únicamente se tuvo que cambiar la llamada síncrona por la ejecución de la tarea (obviamente se movió código dentro de la tarea y se cambiaron algunos puntos de entrada ya que a las tareas solo pueden recibir tipos básicos o estructuras de datos sencillas).
Gracias a esto, se hicieron pruebas con 10.000 registros y las actualizaciones se realizaron con éxito.
En relación a la consulta, solo se hizo un nuevo endpoint que dados los audit_block_ids comprobaba el estado de las tareas y lo retornaba al usuario. Con esta modificación no se vió afectada la ejecución del merge undo.
Empecé hablando del overkill y como hemos visto al final, no hemos matado ninguna mosca con ningún cañón. La última versión del módulo es capaz de resolver el problema con buenos resultados en tiempos aceptables. Además es genérica, escalable y, lo más importante, elegante.











