5 de Diciembre de 2017 · 17 min de lectura

Dentro del compromiso que tiene APSL relacionado con la generación y divulgación de conocimiento, el equipo del departamento de Ciencias de Datos y Machine Learning quiere ofrecer una serie de tutoriales sobre el uso de TensorFlow para el reconocimientos de imágenes.
El objetivo de éstos tutoriales, que se irán publicando periódicamente, es el de ofrecer de manera sencilla y didáctica, a través de ejemplos prácticos, los fundamentos y conceptos básicos esenciales para la tarea de reconocimiento de imágenes. Al acabar la serie habremos desarrollado una aplicación que permita crear una red neuronal en TensorFlow, entrenable y capaz de reconocer nuestra propia base de datos de imágenes.
Para lograrlo empezaremos nuestro camino con ejemplos muy simples donde se irán introduciendo los aspectos básicos de TensorFlow, y que iremos avanzando en nuestros conocimientos hasta alcanzar el objetivo propuesto.
El contenido de estos turoriales están elaborados con la recopilación de distintas fuentes (manuales y blogs), así como con conocimiento adquirido de nuestra experiencia en el desarrollo de aplicaciones propias para distintas tareas en diferentes áreas. En la bibliografía haremos referencia a las diversas fuentes utilizadas.
¡¡¡Comencemos entonces!!!
TensorFlow es una librería de código abierto para cálculo numérico, usando como forma de programación grafos de flujo de datos. Los nodos en el grafo representan operaciones matemáticas, mientras que las conexiones o links del grafo representan los conjuntos de datos multidimensionales (tensores) .
Con esta librería somos capaces, entre otras operaciones, de construir y entrenar redes neuronales para detectar correlaciones y descifrar patrones, análogos al aprendizaje y razonamiento usados por los humanos. Actualmente se utiliza Tensorflow tanto en la investigación como para la producción de productos de Google, remplazando el rol de su predecesor de código cerrado, DistBelief.
TensorFlow es el sistema de aprendizaje automático de segunda generación de Google Brain, liberado como software de código abierto el 9 de noviembre del 2015. Mientras la implementación de referencia se ejecuta en dispositivos aislados, TensorFlow puede correr en múltiple CPUs y GPUs (con extensiones opcionales de CUDA para informática de propósito general en unidades de procesamiento gráfico). TensorFlow está disponible en Linux de 64 bits, macOS, y plataformas móviles que incluyen Android e iOS.
Los cómputos de TensorFlow están expresados como stateful dataflow graphs. El nombre TensorFlow deriva de las operaciones que las redes neuronales realizan sobre arrays multidimensionales de datos. Estos arrays multidimensionales son referidos como "tensores" (más detalles ver https://www.tensorflow.org/).
En este primer tutorial mostraremos el flujo de trabajo básico al usar TensorFlow con un modelo lineal simple. El ejemplo que seguiremos para ello es desarrollar una aplicación que reconozca los dígitos escrito a mano.
Comenzaremos por implementar el modelo más sencillo posible. En este caso, haremos una regresión lineal como primer modelo para el reconocimiento de los dígitos tratados como imágenes.
Primero procederemos a cargar un conjunto de imágenes de los dígitos escrito a mano del conjunto de datos MNIST, luego procederemos a definir y optimizar un modelo matemático de regresión lineal en TensorFlow.
Nota: Algunas nociones básicas sobre Python y alguna comprensión básica sobre Machine Learning ayudan a una mejor comprensión.
Primero cargaremos algunas librería
%matplotlib inline
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
from sklearn.metrics import confusion_matrix
El conjunto de datos MNIST es de aproximadamente 12 MB y se descargará automáticamente si no se encuentra en la ruta dada.
# Load Data.....
from tensorflow.examples.tutorials.mnist import input_data
data = input_data.read_data_sets("data/MNIST/", one_hot=True)
Extracting data/MNIST/train-images-idx3-ubyte.gz
Extracting data/MNIST/train-labels-idx1-ubyte.gz
Extracting data/MNIST/t10k-images-idx3-ubyte.gz
Extracting data/MNIST/t10k-labels-idx1-ubyte.gz
Verificamos los datos
print("Size of:")
print("- Training-set:\t\t{}".format(len(data.train.labels)))
print("- Test-set:\t\t{}".format(len(data.test.labels)))
print("- Validation-set:\t{}".format(len(data.validation.labels)))
Size of: - Training-set: 55000
Test-set: 10000
Validation-set: 5000
Como se observa, ahora tenemos tres sub conjunto de datos, uno de entrenamiento, uno de test y otro de validación.
El conjunto de datos se ha cargado con la codificación denominada One-Hot. Esto significa que las etiquetas se han convertido de un solo número a un vector cuya longitud es igual a la cantidad de clases posibles. Todos los elementos del vector son cero excepto el elemento i ésimo que toma el valor uno; y significa que la clase es i.
Por ejemplo, las etiquetas codificadas de One-Hot para las primeras 5 imágenes en el conjunto de prueba son:
data.test.labels[0:5, :]
se obtiene:
array([[ 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],
[ 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[ 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.]])
Como se observa, tenemos cinco vectores donde cada componete tiene valores cero excepto en la posición de la componete que identifica la clase, cuyo valor es 1.
Como necesitamos las clases como números únicos para las comparaciones y medidas de rendimiento, procedemos a convertir estos vectores codificados como One-Hot a un solo número tomando el índice del elemento más alto. Tenga en cuenta que la palabra 'clase' es una palabra clave utilizada en Python, por lo que necesitamos usar el nombre 'cls' en su lugar.
Para codificar estos vectores a números:
data.test.cls = np.array([label.argmax() for label in data.test.labels])
Ahora podemos ver la clase para las primeras cinco imágenes en el conjunto de pruebas.
print (data.test.cls[0:5])
se obtiene
array([7, 2, 1, 0, 4, 1])
Comparemos estos con los vectores codificados One-Hot de arriba. Por ejemplo, la clase para la primera imagen es 7, que corresponde a un vector codificado One-Hot donde todos los elementos son cero excepto el elemento con índice 7.
El siguiente paso es definir algunas variables que se usaran en el código. Estas variables y sus valores constantes nos permitirá tener un código más limpio y fácil de leer.
Las definimos de la siguiente manera:
# We know that MNIST images are 28 pixels in each dimension.
img_size = 28
# Images are stored in one-dimensional arrays of this length.
img_size_flat = img_size * img_size
# Tuple with height and width of images used to reshape arrays.
img_shape = (img_size, img_size)
# Number of classes, one class for each of 10 digits.
num_classes = 10
Ahora crearemos una función que es utilizada para trazar 9 imágenes en una cuadrícula de 3x3 y escribir las clases verdaderas y predichas debajo de cada imagen.
def plot_images(images, cls_true, cls_pred=None):
assert len(images) == len(cls_true) == 9
# Create figure with 3x3 sub-plots.
fig, axes = plt.subplots(3, 3)
fig.subplots_adjust(hspace=0.5, wspace=0.5)
for i, ax in enumerate(axes.flat):
# Plot image.
ax.imshow(images[i].reshape(img_shape), cmap='binary')
# Show true and predicted classes.
if cls_pred is None:
xlabel = "True: {0}".format(cls_true[i])
else:
xlabel = "True: {0}, Pred: {1}".format(cls_true[i], cls_pred[i])
ax.set_xlabel(xlabel)
# Remove ticks from the plot.
ax.set_xticks([])
ax.set_yticks([])
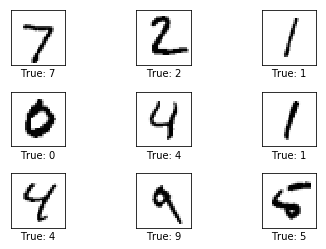
Dibujemos algunas imágenes para ver si los datos son correctos
# Get the first images from the test-set.
images = data.test.images[0:9]
# Get the true classes for those images.
cls_true = data.test.cls[0:9]
# Plot the images and labels using our helper-function above.
plot_images(images=images, cls_true=cls_true)
El propósito de usar la librería de TensorFlow es generar un grafo computacional que se puede ejecutar de manera mucho más eficiente. TensorFlow puede ser más eficiente que NumPy (en algunos casos), puesto que TensorFlow conoce todo el grafo de cálculo y su flujo de datos que debe ejecutarse, mientras que NumPy solo conoce el cálculo de la operación matemática que se este ejecutando en un determinado momento.
TensorFlow también puede calcular automáticamente los gradientes que se necesitan para optimizar las variables del grafo a fin de que el modelo funcione mejor. Esto se debe a que el grafo es una combinación de expresiones matemáticas simples, por lo que el gradiente de todo el grafo se puede calcular utilizando la regla de cadena para el cálculo de las derivadas al optimizar la función de coste.
Un grafo de TensorFlow de manera general consta de las siguientes partes:
Las variables de marcador de posición (Placeholder variables) utilizadas para cambiar las entradas (datos) al grafo (links entre los nodos).
Las variables del modelo.
El modelo, que es esencialmente una función matemática que calcula los resultados dada la entrada en las variables del marcador de posición (Placeholder variables) y las variables del modelo (recuerde que desde el punto de vista de TensorFlow las operaciones matemáticas son tratadas como nodos del grafo).
Una medida de costo que se puede usar para guiar la optimización de las variables.
Un método de optimización que actualiza las variables del modelo.
Además, el grafo TensorFlow también puede contener varias declaraciones de depuración, por ejemplo para que los datos de registro se muestren utilizando TnesorBoard, que no se trata en este tutorial.
Las variables de marcador de posición (Placeholder variables) sirven de entrada al grafo, y que podemos cambiar a medida que ejecutamos operaciones sobre el grafo.
Pasemos a definir las variables de marcador de posición para las imágenes de entrada (Placeholder variables) , a la que llamaremos x. Hacer esto nos permite cambiar las imágenes que se ingresan al grafo de TensorFlow.
El tipo de dato que se introducen en el grafo, son vectores o matrices multidimensionales (denotados tensores). Estos tensores son arrays multidimencionales , cuya forma es [None, img_size_flat], donde None significa que el tensor puede contener un número arbitrario de imágenes, siendo cada imagen un vector de longitud img_size_flat.
Definimos:
x = tf.placeholder(tf.float32, [None, img_size_flat])
Note que en la función tf.placeholder, hemos de definir el tipo de dato, que en éste caso es un float32.
A continuación, definimos la variable de marcador de posición para las etiquetas verdaderas asociadas con las imágenes que se ingresaron en la variable de marcador de posición x. La forma de esta variable de marcador de posición es [None, num_classes], lo que significa que puede contener una cantidad arbitraria de etiquetas y cada etiqueta es un vector de longitud de num_classes, que es 10 en nuestro caso.
y_true = tf.placeholder(tf.float32, [None, num_classes])
Finalmente, tenemos la variable de marcador de posición para la clase verdadera de cada imagen en la variable de marcador de posición x. Estos son enteros y la dimensionalidad de esta variable de marcador de posición se pre-define como [None], lo que significa que la variable marcador de posición es un vector unidimensional de longitud arbitraria.
y_true_cls = tf.placeholder(tf.int64, [None])
Como hemos indicado anteriormente, en éste ejemplo vamos a emplear un simple modelo matemático de regresión lineal, es decir, que vamos a definir una función lineal donde se multiplica las imágenes en la variable de marcador de posición $x$ por una variable $w$ que llamaremos pesos y luego agrega un sesgos (bias) que llamaremos $b$.
Por tanto:
\begin{equation} logist = w x + b \end{equation}
El resultado es una matriz de forma [num_images, num_classes] , dado que $x$ tiene la forma [num_images, img_size_flat] y la matriz de pesos $w$ tienen la forma [img_size_flat, num_classes], por lo que la multiplicación de éstas dos matrices es una matriz con cuya forma es [num_images, num_classes] . Luego el vector de sesgos $b$ se agrega a cada fila de esa matriz resultante.
Nota hemos usado el nombre $logits$ para respetar la terminología típica de TensorFlow, pero se puede llamar a la variable de otra manera.
Esta operación en TensorFlow la definimos de la siguiente manera:
w = tf.Variable(tf.zeros([img_size_flat, num_classes]))
b = tf.Variable(tf.zeros([ num_classes]))
logits = tf.matmul(x, w) + b
En la definición del modelo $logits$, hemos usado la función tf.matmul. Esta función nos devuelve el valor de multiplicar el tensor $x$ por el tensor $w$.
El modelo logits es una matriz con filas num_images y columnas num_classes, donde el elemento de la fila $i$ enésima y la columna $j$ enésima es una estimación de la probabilidad de que la imagen de entrada $i$ enésima sea de la $j$ enésima clase.
Sin embargo, estas estimaciones son un poco difíciles de interpretar, dado que los números que se obtienen pueden ser muy pequeños o muy grandes. El siguiente paso entonces sería normalizar los valores de tal modo que, para que cada fila de la matriz $logits$ todos sus valores sumen uno, así el valor de cada elemento de la matriz esté restringido entre cero y uno. Con TensorFlow, esto se calcula utilizando la función llamada softmax y el resultado se almacena en una nueva variable y_pred.
y_pred = tf.nn.softmax(logits)
Finalmente la clase predicha puede calcularse a partir de la matriz y_pred tomando el índice del elemento más grande en cada fila.
y_pred_cls = tf.argmax(y_pred, dimension=1)
Como hemos indicado anteriormente, el modelo de clasificación y reconocimiento de los dígitos escrito a mano que hemos implementado, es un modelo matemático de regresión lineal $logits = wx + b$. La calidad de predicción del modelo va depender de los valores óptimos de las variables $w$ (tensor de pesos) y $b$ (tensor de sesgos) data una entrada $x$ (tensor de imágenes). Por tanto, optimizar nuestro clasificador para la tarea del reconocimiento de los dígito consiste en hacer un ajuste de nuestro modelo de tal forma que podamos encontrar los valores óptimos en el tensor $w$ y $b$. Este proceso de óptimización en éstas variables es lo que se conoce como el proceso de entrenamiento o aprendizaje del modelo.
Para mejorar el modelo al clasificar las imágenes de entrada, de alguna manera debemos encontrar un método para cambiar el valor de las variables para las ponderaciones ($w$) y los sesgos ($b$). Para hacer esto, primero necesitamos saber qué tan bien funciona actualmente el modelo al comparar el resultado predicho del modelo y_pred con el resultado deseado y_true. La función de rendimiento que mide el error entre la salida real del sistema que se pretende modelar y la salida del núcleo estimador (el modelo) , es lo que se conoce como función de coste. Diferentes funciones de coste se pueden definir.
La entropía cruzada (cross-entropy) es una medida de rendimiento utilizada en la clasificación. La entropía cruzada es una función continua que siempre es positiva y si la salida predicha del modelo coincide exactamente con la salida deseada, entonces la entropía cruzada es igual a cero. Por lo tanto, el objetivo de la optimización es minimizar la entropía cruzada para que se acerque lo más posible a cero cambiando los pesos $w$ y los sesgos $b$ del modelo.
TensorFlow tiene una función incorporada para calcular la entropía cruzada. Note que se usan los valores de los $logits$ puesta que esta función del tensorFlow calcula el softmax internamente.
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits,labels=y_true)
Una vez que hemos calculado la entropía cruzada para cada una de las clasificaciones de imágenes, tenemos una medida de qué tan bien se comporta el modelo en cada imagen individualmente. Pero para usar la entropía cruzada para guiar la optimización de las variables del modelo, necesitamos tener un solo valor escalar, así que simplemente tomamos el promedio de la entropía cruzada para todas las clasificaciones de imágenes.
Para esto:
cost = tf.reduce_mean(cross_entropy)
Ahora que ya tenemos una medida de costo que debe minimizarse, podemos crear un optimizador. En este caso usaremos uno de los métodos maś utilizado conocido como Gradient Descent (para más detalles revisar lecture 4, lecture 5 y lecture 6), donde el tamaño de paso para el ajuste de las varuable lo prefijamos en en 0.5.
Tenga en cuenta que la optimización no se realiza en este momento. De hecho, nada se calcula en absoluto, simplemente agregamos el objeto optimizador al gráfico TensorFlow para su posterior ejecución.
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.5).minimize(cost)
Necesitamos algunas medidas de rendimiento más para mostrar el progreso al usuario. Creamos una un vector de booleanos, dónde donde verificamos si la clase predicha es igual a la clase verdadera de cada imagen.
correct_prediction = tf.equal(y_pred_cls, y_true_cls)
Esto calcula la precisión (accuracy) de la clasificación y transforma los booleanos a floats, de modo que False se convierte en 0 y True se convierte en 1. Luego calculamos el promedio de estos números.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
Una vez espcificados todos los elementos de nuestro modelo, podemos ya crear el grafo. Para ello tenemos que crear una sesión para ejecutar luego el grafo:
session = tf.Session()
Inicializar variables: Las variables para pesos y sesgos deben inicializarse antes de comenzar a optimizarlas.
session.run(tf.global_variables_initializer())
Al tener 50.000 imágenes en el conjunto de entrenamiento, puede llevar mucho tiempo calcular el gradiente del modelo usando todas estas imágenes a durante el proceso de optimización. Por lo tanto, usamos un Stochastic Gradient Descent que solo usa un lote (bacth) de imágenes en seleccionada aleatoriamente cada iteración del optimizador. Esto permite que el proceso de aprendizaje sea más rápido.
Creamos una función para realizar varias iteraciones de optimización para mejorar gradualmente los pesos $w$ y los sesgos $b$ del modelo. En cada iteración, se selecciona un nuevo lote de datos del conjunto de entrenamiento y luego TensorFlow ejecuta el optimizador utilizando esas muestras de entrenamiento. Fijamos eso lote de imágenes em 100 (batch_size = 100 ).
# bacth of images
batch_size = 100
def optimize(num_iterations):
for i in range(num_iterations):
# Get a batch of training examples.
# x_batch now holds a batch of images and
# y_true_batch are the true labels for those images.
x_batch, y_true_batch = data.train.next_batch(batch_size)
# Put the batch into a dict with the proper names
# for placeholder variables in the TensorFlow graph.
# Note that the placeholder for y_true_cls is not set
# because it is not used during training.
feed_dict_train = {x: x_batch,
y_true: y_true_batch}
# Run the optimizer using this batch of training data.
# TensorFlow assigns the variables in feed_dict_train
# to the placeholder variables and then runs the optimizer.
session.run(optimizer, feed_dict=feed_dict_train)
Vamos a crear un conjunto de funciones que nos ayudaran a monitorizar el rendimiento de nuestro clasificador. Primero creamos un diccionario con los datos del conjunto de prueba que se utilizarán como entrada al grafo de TensorFlow.
feed_dict_test = {x: data.test.images,
y_true: data.test.labels,
y_true_cls: data.test.cls}
Función para imprimir la precisión (accuracy) de clasificación en el conjunto de prueba.
def print_accuracy():
# Use TensorFlow to compute the accuracy.
acc = session.run(accuracy, feed_dict=feed_dict_test)
# Print the accuracy.
print("Accuracy on test-set: {0:.1%}".format(acc))
Función para imprimir y trazar la matriz de confusión usando scikit-learn.
def print_confusion_matrix():
# Get the true classifications for the test-set.
cls_true = data.test.cls
# Get the predicted classifications for the test-set.
cls_pred = session.run(y_pred_cls, feed_dict=feed_dict_test)
# Get the confusion matrix using sklearn.
cm = confusion_matrix(y_true=cls_true,
y_pred=cls_pred)
# Print the confusion matrix as text.
print(cm)
# Plot the confusion matrix as an image.
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
# Make various adjustments to the plot.
plt.tight_layout()
plt.colorbar()
tick_marks = np.arange(num_classes)
plt.xticks(tick_marks, range(num_classes))
plt.yticks(tick_marks, range(num_classes))
plt.xlabel('Predicted')
plt.ylabel('True')
Función para trazar los pesos del modelo. Se trazan 10 imágenes, una para cada dígito en el que el modelo está entrenado para reconocerlo.
def plot_weights():
# Get the values for the weights from the TensorFlow variable.
wi = session.run(w)
# Get the lowest and highest values for the weights.
# This is used to correct the colour intensity across
# the images so they can be compared with each other.
w_min = np.min(wi)
w_max = np.max(wi)
# Create figure with 3x4 sub-plots,
# where the last 2 sub-plots are unused.
fig, axes = plt.subplots(3, 4)
fig.subplots_adjust(hspace=0.3, wspace=0.3)
for i, ax in enumerate(axes.flat):
# Only use the weights for the first 10 sub-plots.
if i<10:
# Get the weights for the i'th digit and reshape it.
# Note that w.shape == (img_size_flat, 10)
image = wi[:, i].reshape(img_shape)
# Set the label for the sub-plot.
ax.set_xlabel("Weights: {0}".format(i))
# Plot the image.
ax.imshow(image, vmin=w_min, vmax=w_max, cmap='seismic')
# Remove ticks from each sub-plot.
ax.set_xticks([])
ax.set_yticks([])
Ahora que ya temos todo lo necesario, vamos a ejecutar el clasificador y hacer alguans pruebas de rendimiento.
Como ya hemos inicializado las variables, lo primero que vamos a mirar es ver el nivel de precision que éste tiene antes de ejecutar cualquier optimización.
ejecutemos la funcion accuracy que hemos creado:
print_accuracy()
Optemos
Accuracy on test-set: 9.8%
La precisión en el conjunto de prueba es 9.8%. Esto se debe a que el modelo solo se ha inicializado y no se ha optimizado en absoluto.
Vamos a usar la función de optimización que hemos creado a una interación:
optimize(num_iterations=1)
print_accuracy()
Resultado:
Accuracy on test-set: 40.9%
Como se aprecia después de una única iteración de optimización, el modelo ha incrementado su precisión en el conjunto de prueba a 40.7%. Esto significa que clasifica incorrectamente las imágenes aproximadamente 6 de cada 10 veces.
Los pesos del tensor $w$ también pueden trazarse como se muestra a continuación. Los pesos positivos toman los tonos rojos y los pesos negativos los tonos azules. Estos pesos pueden entenderse intuitivamente como filtros de imagen.
Usemos la funcion plot_weights()
plot_weights()
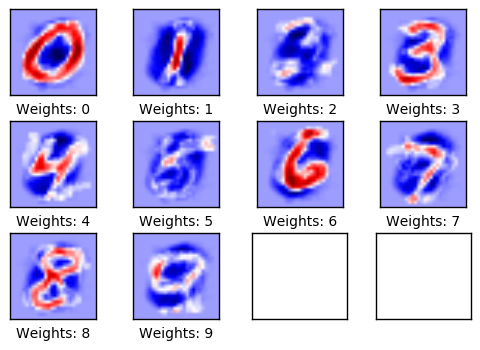
Por ejemplo, los pesos utilizados para determinar si una imagen muestra un dígito cero tienen una reacción positiva (roja) como la imagen de un círculo y tienen una reacción negativa (azul) a las imágenes con contenido en el centro del círculo.
De manera similar, los pesos utilizados para determinar si una imagen muestra el dígito 1, éste reacciona positivamente (rojo) a una línea vertical en el centro de la imagen, y reacciona negativamente (azul) a las imágenes con el contenido que rodea esa línea.
En estas imágenes, los pesos en su mayoría se parecen a los dígitos que se supone deben reconocer. Esto se debe a que solo se ha realizado una iteración de optimización, por lo que los pesos solo se entrenan en 100 imágenes. Después de entrenar en miles de imágenes, los pesos se vuelven más difíciles de interpretar porque tienen que reconocer muchas variaciones de cómo se pueden escribir los dígitos.
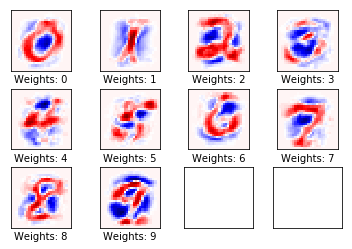
Redimiento después de 10 iteraciones
# We have already performed 1 iteration.
optimize(num_iterations=9)
print_accuracy()
resultado:
Accuracy on test-set: 78.2%
Los pesos
plot_weights()
Rendimiento después de 1000 iteraciones de optimización
# We have already performed 1000 iteration.
optimize(num_iterations=999)
print_accuracy()
plot_weights()
Obtenemos:
Accuracy on test-set: 92.1%
pesos
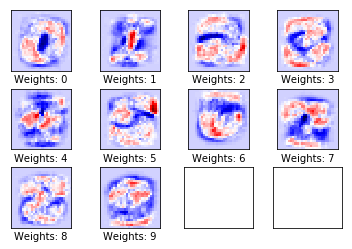
Después de 1000 iteraciones de optimización, el modelo solo clasifica erróneamente una de cada diez imágenes. Este modelo simple no puede alcanzar un rendimiento mucho mejor y, por lo tanto, se necesitan modelos más complejos. En los subsiguientes tutoriales crearemos un medelo más complejo usando redes neuronales que nos ayudará mejorar el rendimiento del nuestro clasificador.
Finalmente para tener una visión global de los errores cometidos por nuestro clasificador, vamos a analizar la matriz de confusión (confusion matrix). Usamos nuestyra función print_confusion_matrix().
print_confusion_matrix()
[[ 961 0 0 3 0 7 3 4 2 0]
[ 0 1097 2 4 0 2 4 2 24 0]
[ 12 8 898 23 5 4 12 12 49 9]
[ 2 0 10 927 0 28 2 9 24 8]
[ 2 1 2 2 895 0 13 4 10 53]
[ 10 1 1 37 6 774 17 4 36 6]
[ 13 3 4 2 8 19 902 3 4 0]
[ 3 6 21 12 5 1 0 936 2 42]
[ 6 3 6 18 8 26 10 5 883 9]
[ 11 5 0 7 17 11 0 16 9 933]]

Ahora que hemos terminado de usar TensorFlow, cerramos la sesión para liberar sus recursos.
session.close()
Con esto finalizamos el primer tutorial sobre como usar la librería de TensorFlow para crear un modelo de regresión lineal.
En la próximas entregas iremos crearemos modelos más complejos, inclueyeno redes neuronales convolucionales.









